
在本篇文章中,我会对Neo4j Graph Data Science进行介绍,并且使用其中的算法做相似分析,这样可以让你更快的了解Neo4j Graph Data Science,并将其应用到实践中。
本文是全系列中的第2/3篇
-
Neo4j和知识图谱:Neo4j内置算法库的安装和使用
Neo4j Graph Data Science介绍
The Neo4j Graph Data Science (GDS) library provides efficiently implemented, parallel versions of common graph algorithms, exposed as Cypher procedures. Additionally, GDS includes machine learning pipelines to train predictive supervised models to solve graph problems, such as predicting missing relationships.
这是官网的介绍,接下来我也将称Neo4j Graph Data Science 为GDS。GDS提供了图算法,同时也可以用于机器学习。
根据处理问题类型,算法分为以下几类:
-
中心性
-
社区
-
相似度
-
路径寻找
-
节点嵌入
-
拓扑链路预测
这篇文章后面会介绍相似分析的案例。
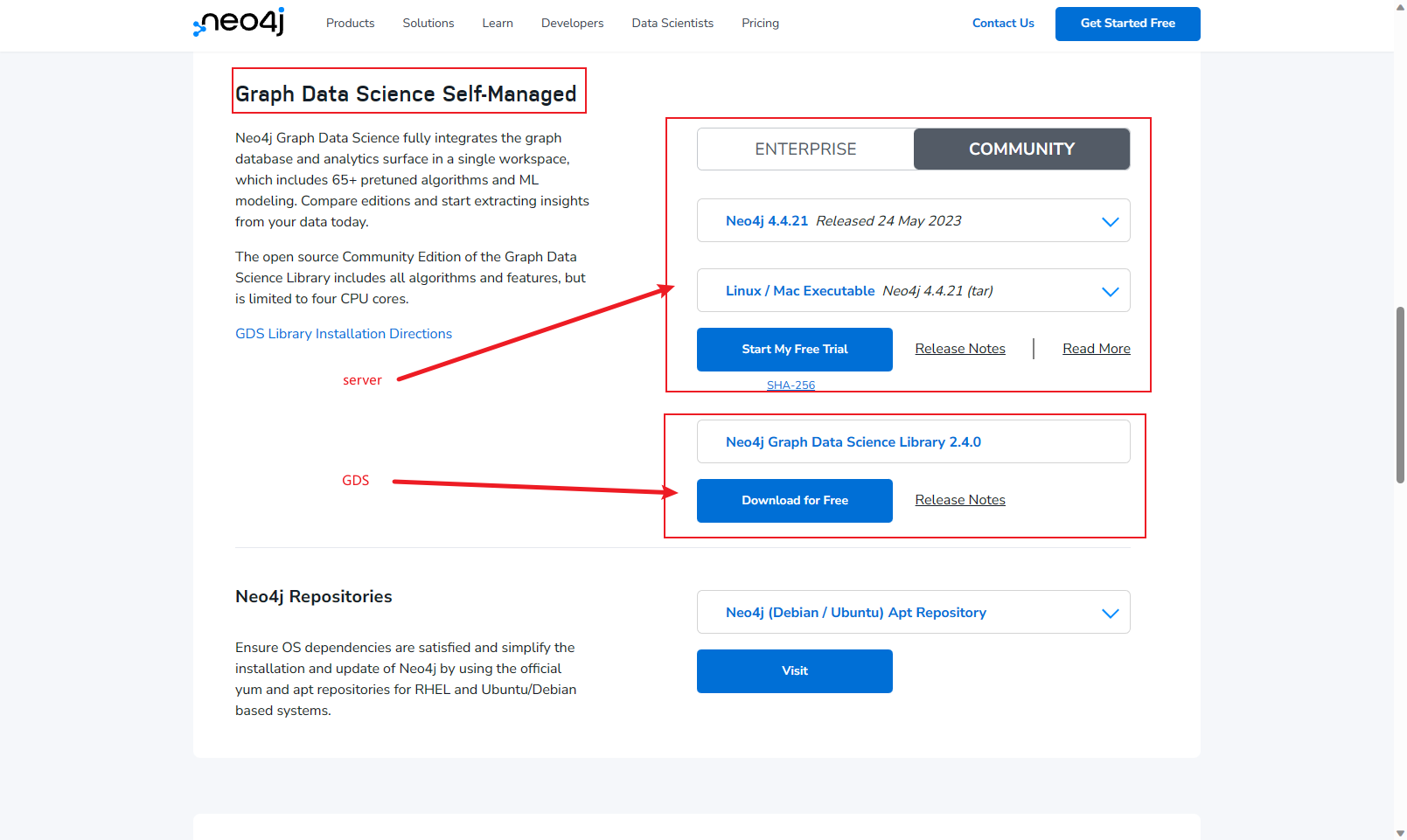
GDS安装
下载GDS包,下载地址
|
|
相似分析
相似分析主要是通过分析两个节点的共有相邻的节点来进行相似分析的。
对于两个集合A和B,Jaccard相似度计算为:

重叠系数使用下面的公式:

对于数据库中的两个节点n和m,A就是和n所有相邻的节点的集合,同样的B是m相邻节点的集合
Neo4j中的相似算法提供了许多有用的功能,适用于各种场景。以下是一些常见的使用场景:
-
推荐系统:通过计算节点之间的相似性,可以构建基于内容或基于协同过滤的推荐系统。相似算法(如相似度计算或最短路径)可以帮助发现相似的用户、产品或兴趣,并向用户提供个性化的推荐。
-
社交网络分析:相似算法可以帮助发现社交网络中的相似用户、群组或兴趣。例如,可以使用相似度算法(如Jaccard相似系数)来寻找在兴趣或活动上具有相似性的用户。
-
产品推荐:相似算法可以帮助发现产品之间的相似性,从而实现商品推荐和交叉销售。通过计算产品之间的相似度,可以根据用户的购买历史或兴趣,向其推荐类似的产品。
-
知识图谱分析:相似算法可以用于分析和比较知识图谱中的实体、关系或概念。通过计算实体之间的相似度,可以发现潜在的关联和模式,并进行语义推理。
相似分析实战
数据准备
|
|
这样我们就建立了一个如下的关系图
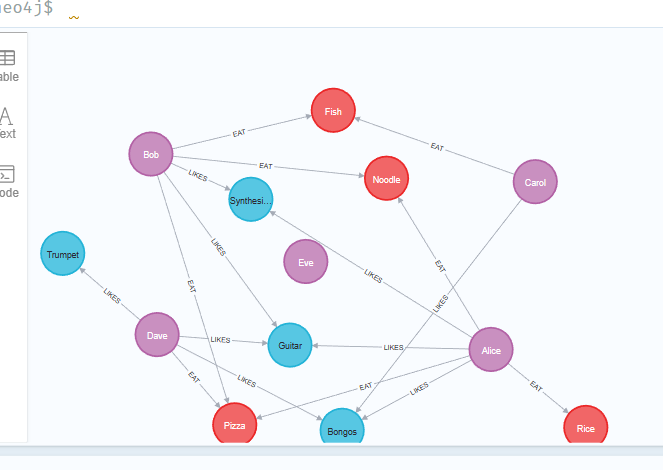
建立投影
|
|
这样我们就建立了两个投影,graph中包含了Person和Instrument节点,graph1中包含了Person、Instrument和Food1节点
计算相似度
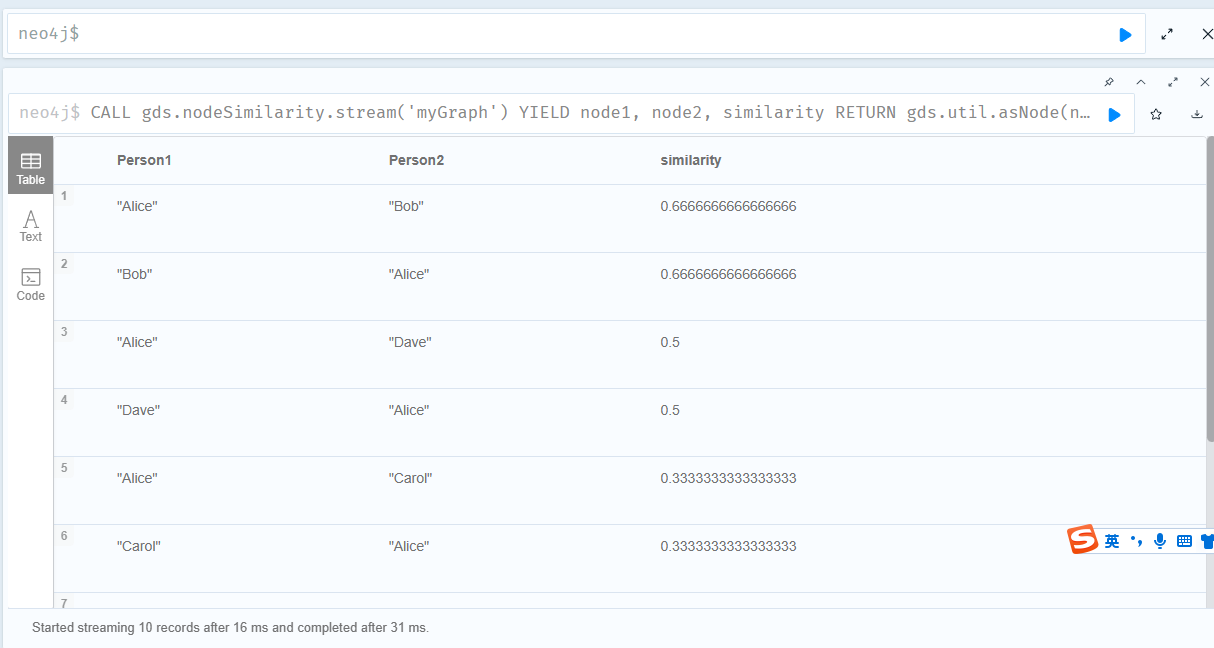
1.计算所有节点的相似度
|
|
语法解析:
- CALL gds.nodeSimilarity.stream(‘myGraph’) 在myGraph投影中使用nodeSimilarity相似分析算法
- YIELD node1, node2, similarity 使用节点node1、node2和相似度similarity
- RETURN gds.util.asNode(node1).name AS Person1, gds.util.asNode(node2).name AS Person2, similarity 返回结果
- ORDER BY similarity DESCENDING, Person1, Person2 排序方式
2.计算myGraph投影中与Alice的相似度
|
|
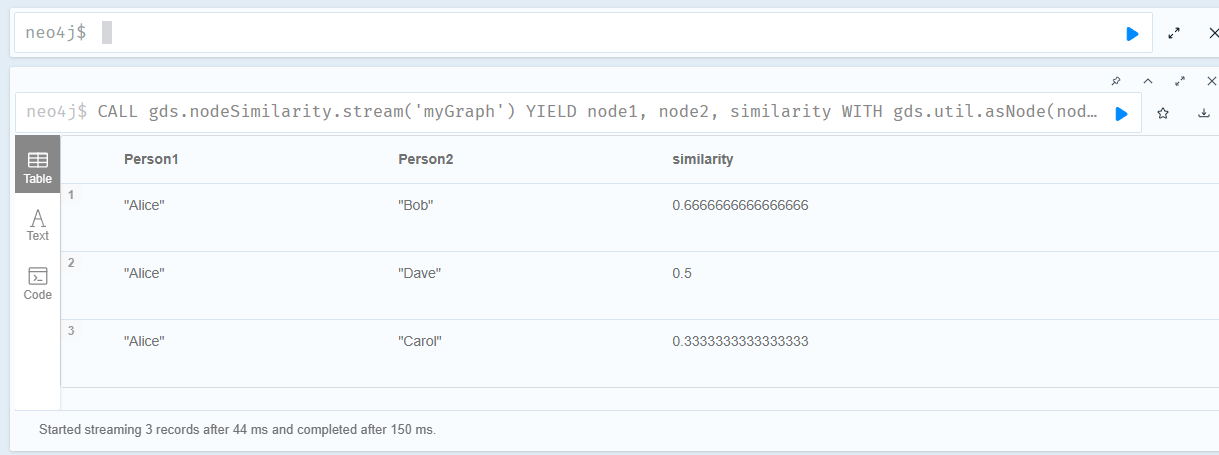
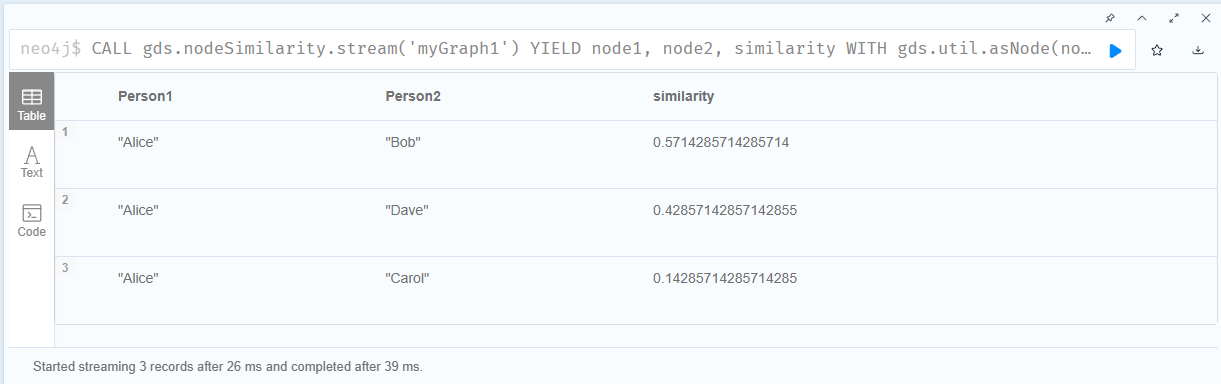
3.计算myGraph1投影中与Alice的相似度
|
|
4.添加关系之后再计算与Alice的相似度 需要删除投影之后再重新建立(投影在建立的时候就已经固定了,更新了关系之后需要更新投影)
|
|
执行结果如下:
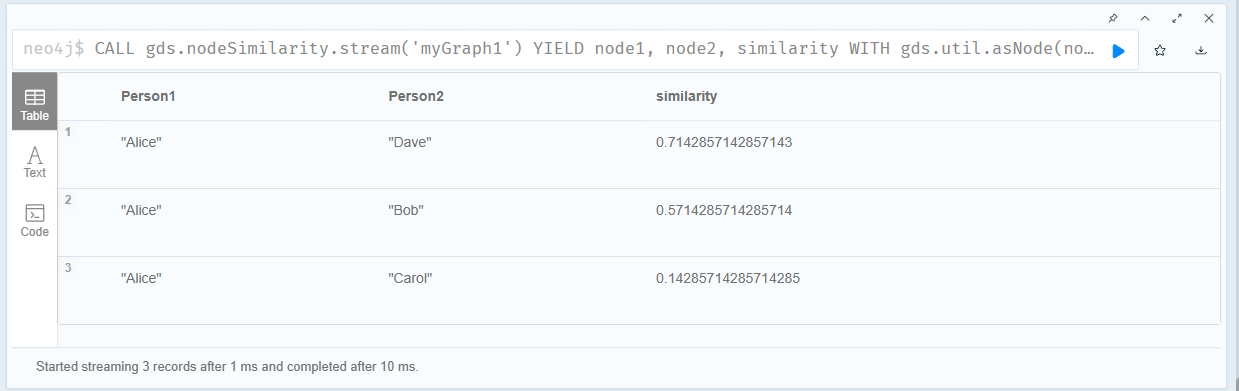 现在是alice最相似的是bob了
现在是alice最相似的是bob了