大模型介绍
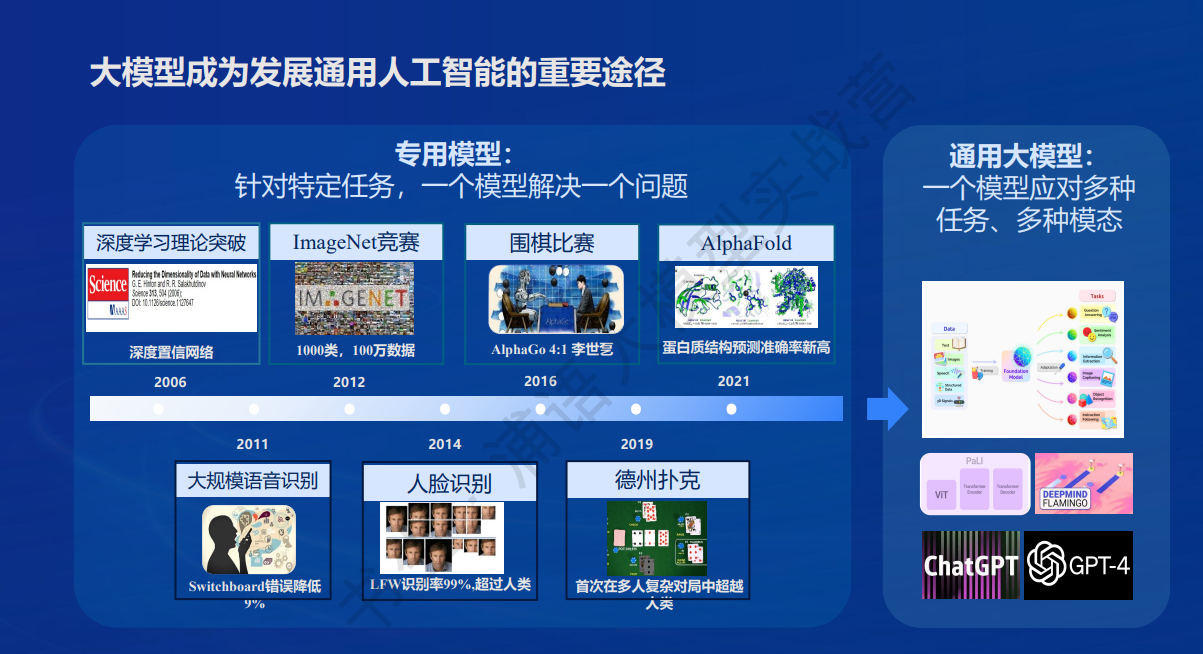
首先介绍一下专用模型,专用模型是针对特定任务或特定领域设计和训练的模型。这些模型通常参数较少、结构较简单,但在特定任务上表现非常出色。比如在nlp领域,关键词提取可以使用jieba里面的TextRank算法,摘要提取可以使用Randeng-Pegasus-523M-Summary-Chinese,纠错可以使用ERNIE-CSC。在图像、语音等其他领域也有各种专用模型。
而大模型是具有大量参数、能够处理广泛任务的通用模型。这些模型在多个领域和任务上都表现出色,通常需要大量计算资源和数据进行训练。比如chatpdf中输入一篇文章,可以让它分析出关键词、摘要等。可以通过一个大模型解决多个问题。
大模型已经成为人工智能发展的最热门的词,自从ChatGPT问世以来,这一趋势更加明显。ChatGPT作为大规模语言模型的代表,以其卓越的自然语言理解和生成能力,迅速引起了广泛关注,并在多个领域展现了强大的应用潜力。
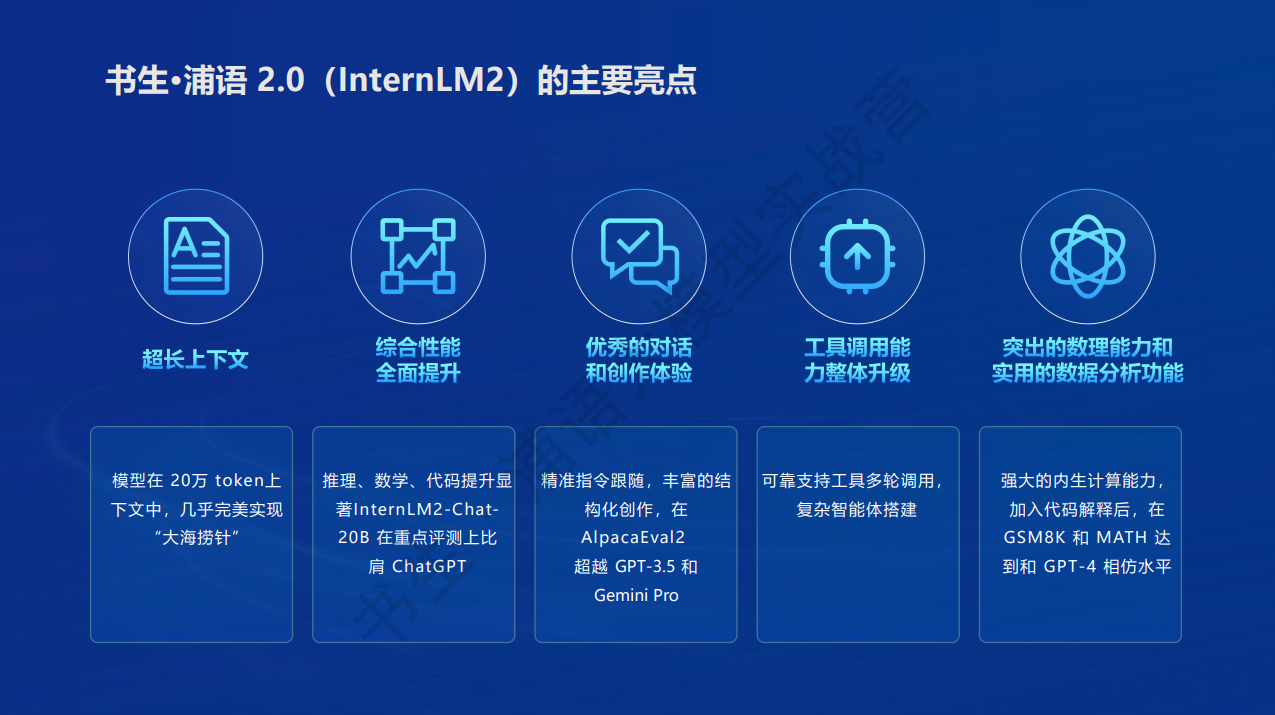
书生·浦语2.0介绍
上海人工智能实验室与商汤科技联合香港中文大学和复旦大学正式发布新一代大语言模型书⽣·浦语2.0(InternLM2)。InternLM2 的核心理念在于回归语言建模的本质,致力于通过提高语料质量及信息密度,实现模型基座语言建模能力获得质的提升,进而在数理、代码、对话、创作等各方面都取得长足进步,综合性能达到同量级开源模型的领先水平。
InternLM2发布了7B和20B两个规格,同时每个规格分别提供InternLM2-Base、InternLM2和InternLM2-Chat三种模型版本。
InternLM2的主要亮点包括:超长上下文、综合性能提升、优秀的对话和创作体验、工具调用整体能力的提升、突出的数理能力和实用的数据分析功能。其中,超长上下文可以实现在20 万字长输入中几乎完美地实现长文“大海捞针”,配合代码解释器可以进行积分求解。
书生·浦语开源开放体系
书生·浦语开源开放体系包含数据、预训练、微调、部署、评测、应用这几个方面。
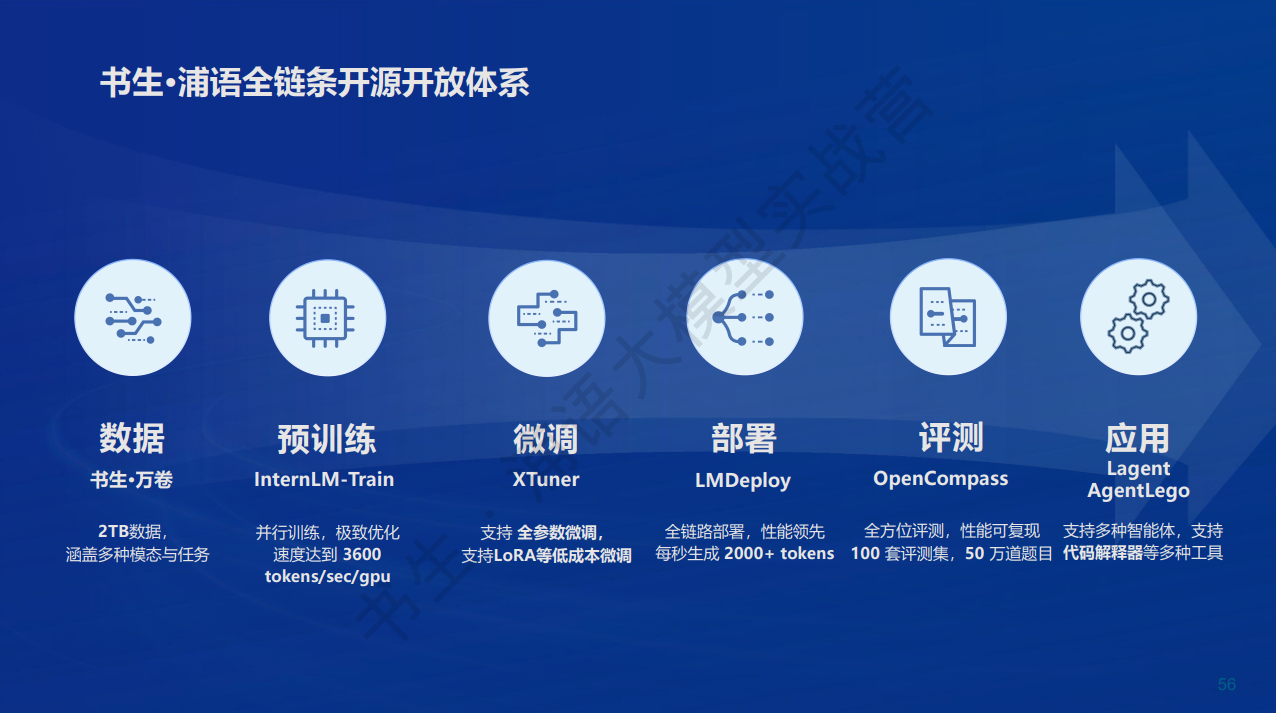
其中介绍我比较感兴趣的微调和部署这两个方面。
微调可以采用书生·浦语开放的高效微调框架 XTuner,XTuner支持加载HuggingFace、ModelScope 模型或数据集,支持训练多种模型,最低只需 8GB 显存即可微调 7B模型。微调分为增量续训和有监督微调。增量续训的用场景为让基座模型学习到一些新知识,如某个垂类领域知识,训练数据有文章、书籍、代码等。有监督微调的使用场景为让模型学会理解各种指令进行对话,或者注入少量领域知识,训练数据为高质量的对话、问答数据。
部署使用LMDeploy,LMDeploy提供大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理和服务。可以实现模型的快速部署。