RAG介绍
RAG(Retrieval Augmented Generation),字面意思就是 检索 - 增强 - 生成。通过检索向量库找到相关文本,再通过特定的prompt使用大模型的能力进行解答。
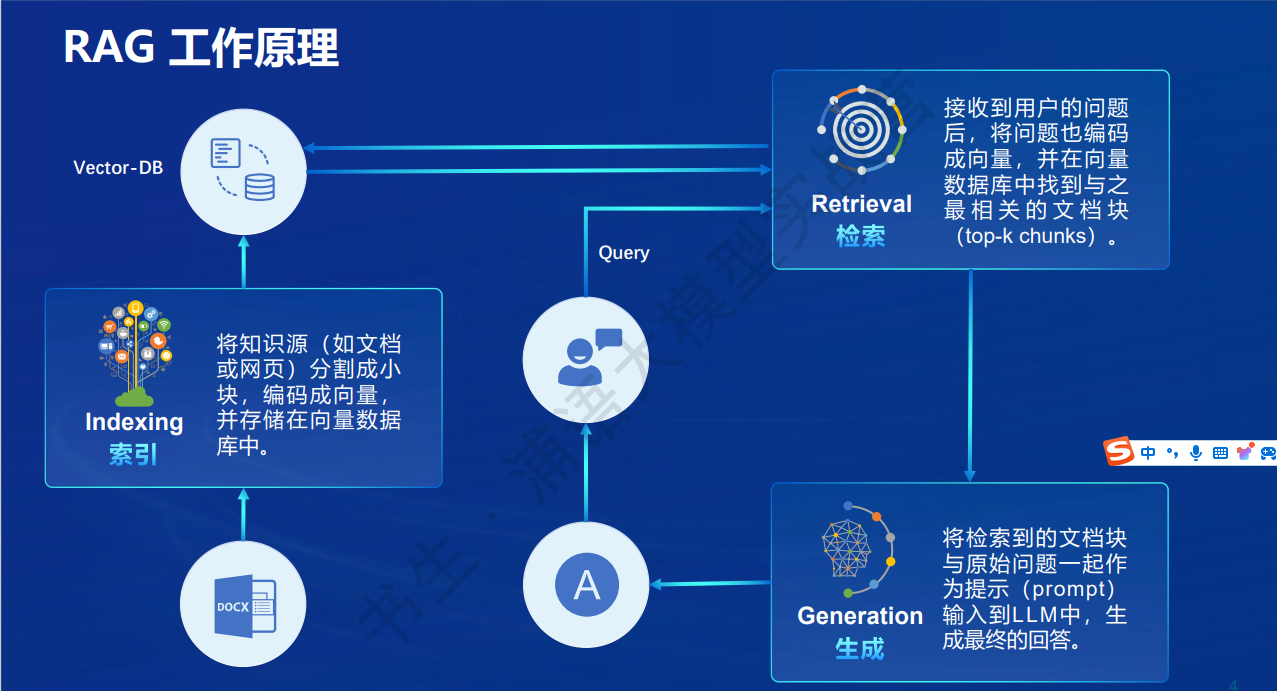
具体步骤如下:
-
先将文档知识加载。其中就可能就有ocr图片识别,同时对于长的文档还需要进行切分。
-
入向量库。一般是通过embedding模型将切分的文本片段进行向量化,加载到向量库中。
-
处理用户问题。用户输入问题时,将用户问题也通过embedding模型进行向量化,之后在通过余弦距离等找出相似的TopN个文本片段。
-
组装prompt,用llm大模型进行回答。将上一步搜索出来的文本片段和用户问题组装好,输入给大模型,让大模型进行回答。 例如:
1 2 3 4 5 6"文本信息内容如下. \n" "---------------------\n" "{context_str}" "\n---------------------\n" "请使用上面的内容信息进行回答,而不是根据模型已有的知识,如果上面的内容信息没有答案,就回复不知道, " "回答这个问题: {query_str}\n"
rag可以解决以下问题: 1.大模型回答幻觉,模型对于不知道的知识可能会一本正经的胡说八道. 2.过时知识,因为模型训练的成本较高,不可能一直更新模型,对于近期的知识,模型是不知道的。使用rag技术可以先通过搜索将近期知识作为问题的一部分输入给模型,使用模型的能力对问题进行回答。 3.可以追溯回答来源。这一点在一些场景非常重要,对于问题回答的可溯源,增加可信的程度。
RAG vs 微调

对于特定任务,即使通过prompt调整也不一定可以获得很好的效果,比如摘要总结这一个具体类型的任务,使用微调是更好的。 而对于结合知识进行回答的场景,RAG则有着它的优势。
茴香豆
茴香豆是一款可以嵌入到IM工具流中的RAG应用
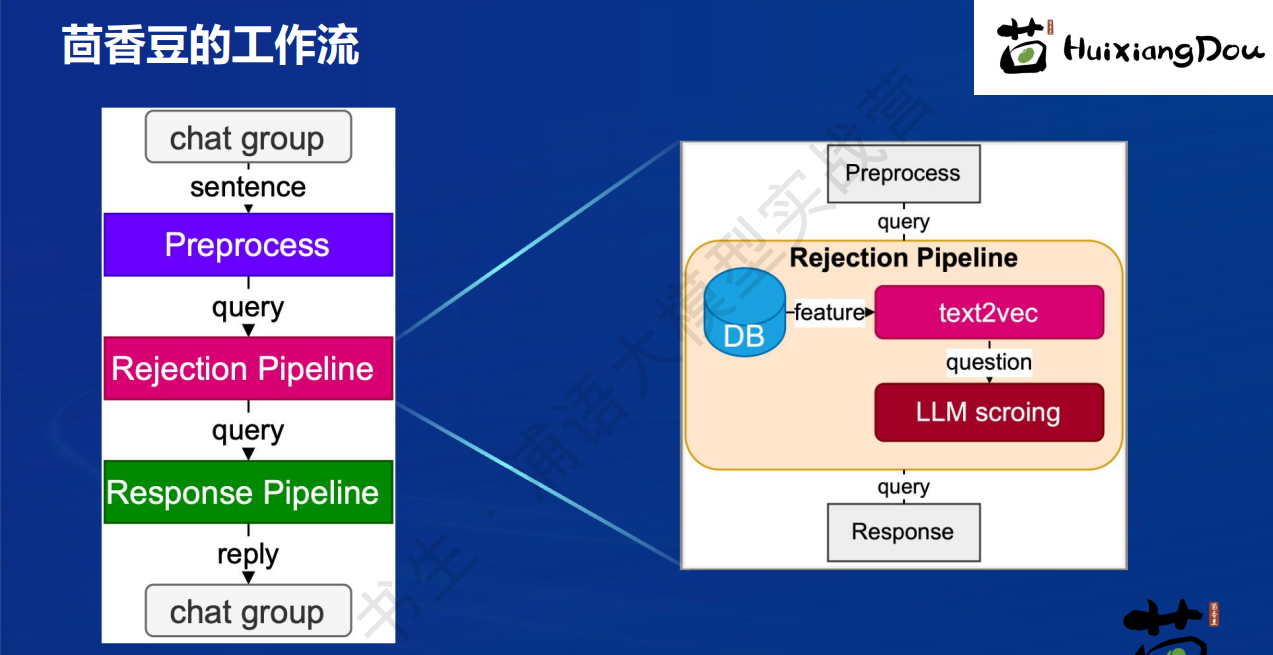
工作流中有rejection pipeline,可以针对无意义的闲聊进行过滤。
线上茴香豆助手对话截图